In R, we do things using functions, as long as we use it beyond a calculator.
Modularity: Functions allow us to break down complex problems into smaller, manageable pieces. During development, we can focus on one function at a time rather than being overwhelmed by an entire project.
Scope management: In long scripts with hundreds or thousands of variables, functions provide local scope. Variables defined inside a function remain local and won’t interfere with variables outside the function. Only inputs and outputs interact with the global environment.
Code reusability and DRY principle: Functions embody the “Don’t Repeat Yourself” (DRY) principle. When we need to make changes, we only need to modify the function definition in one place. This eliminates the need to update the same code in multiple locations throughout our script, reducing errors and maintenance overhead.
We have already seen and used a multitude of functions in R. Some of these functions come pre-packaged with base R (e.g. mean()), while others are from external packages (e.g. mvtnorm::rmvnorm()).
Regardless of where they come from, functions in R all adopt the same basic syntax:
function_name(ARGUMENTS)
For much of the time, we will rely on functions that other people have written for us. However, you can — and should! — write your own functions too. This is easy to do with the generic function() function.1 The syntax will again look familiar to you:
function(ARGUMENTS) { OPERATIONSreturn(VALUE)}
While it’s possible and reasonably common to write anonymous functions like the above, we typically write functions because we want to reuse code. For this typical use-case it makes sense to name our functions.2
For some short functions, you don’t need to invoke the curly brackets or assign an explicit return object (more on this below). In these cases, you can just write your function on a single line:
my_short_func =function(ARGUMENTS) OPERATION
Tip
Try to give your functions short, pithy names that are informative to both you and anyone else reading your code. This is harder than it sounds, but will pay off down the road.
Simple Example: Addition
# Built-in functionsum(c(3, 4))
[1] 7
# User-defined functionadd_func <-function(x, y){ total <- x + y ## Create an intermediary object (that will be returned)return(total) ## The value(s) or object(s) that we want returned.}add_func(3, 4)
[1] 7
Caution
R’s default behaviour is to automatically return the final object that you created within the function. However, this won’t always be the case. I thus advise that you get into the habit of assigning the return object(s) explicitly.
Specifying an explicit return value is also helpful when we want to return more than one object. For example, let’s say that we want to remind our user what variable they used as an argument in our function:
add_func <-function(x, y){ total <- x + yreturn(list(sum = total, first_element = x, second_element = y))}add_func(3, 4)
Note that multiple return objects have to be combined in a list. I didn’t have to name these separate list elements — i.e. “sum”, “first_element” and “second_element” — but it will be helpful for users of our function.
Note that for this simple example we could have written everything on a single line:
my_short_add_func <-function(x, y) x + ymy_short_add_func(3, 4)
[1] 7
Specifying default argument values
Another thing worth noting about R functions is that you can assign default argument values. You have already encountered some examples of this in action.3 We can add a default option to our own function pretty easily.
add_func <-function(x =1, y =1){ total <- x + yreturn(list(total, first_element = x, second_element = y))}add_func()
Before continuing, I want to highlight the fact that none of the intermediate objects that we created within the above functions (total, etc.) have made their way into our global environment. Take a moment to confirm this for yourself by looking in the “Environment” pane of your RStudio session.
R has a set of so-called lexical scoping rules, which govern where it stores and evaluates the values of different objects. Without going into too much depth, the practical implication of lexical scoping is that functions operate in a quasi-sandboxed environment. They don’t return or use objects in the global environment unless they are forced to (e.g. with a return() command). Similarly, a function will only look to outside environments (e.g. a level “up”) to find an object if it doesn’t see the object named within itself.
Example: OLS estimation
In introductory econometrics/statistics courses, you have probably seen the formula for OLS estimation. Consider a simple linear regression model with a constant term and one regressor:
\[y_i = \beta_0 + \beta_1 x_i + \varepsilon_i\]
where \(y_i\) is the dependent variable, \(x_i\) is the independent variable, \(\beta_0\) is the intercept, \(\beta_1\) is the slope coefficient, and \(\varepsilon_i\) is the error term for observation \(i\).
In matrix notation, this can be written as: \[\mathbf{y} = \mathbf{X}\boldsymbol{\beta} + \boldsymbol{\varepsilon}\]
where:
\(\mathbf{y}\) is an \(n \times 1\) vector of dependent variable observations
\(\mathbf{X}\) is an \(n \times 2\) matrix where the first column is all ones (for the intercept) and the second column contains the \(x_i\) values
\(\boldsymbol{\beta} = \begin{bmatrix} \beta_0 \\ \beta_1 \end{bmatrix}\) is a \(2 \times 1\) vector of parameters
\(\boldsymbol{\varepsilon}\) is an \(n \times 1\) vector of error terms
The OLS estimator is given by: \[\hat{\boldsymbol{\beta}} = (\mathbf{X}' \mathbf{X})^{-1} \mathbf{X}'\mathbf{y}\]
To conduct OLS estimation in R, we literally translate this mathematical expression into code.
Step 1: We need data \(Y\) and \(X\) to run OLS. We simulate an artificial dataset.
# simulate dataset.seed(111) # can be removed to allow the result to change# set the parametersn <-100b0 <-matrix(1, nrow =2 )# generate the datae <-rnorm(n)X <-cbind( 1, rnorm(n) )Y <- X %*% b0 + e# Snapshot of X (first 10 rows):print(head(X, 10))
# Use built-in functionsbhat_3 <-lsfit(X, Y, intercept =FALSE)$coefficientsprint(bhat_3)
X1 X2
0.9861773 0.9404956
class(bhat_3)
[1] "numeric"
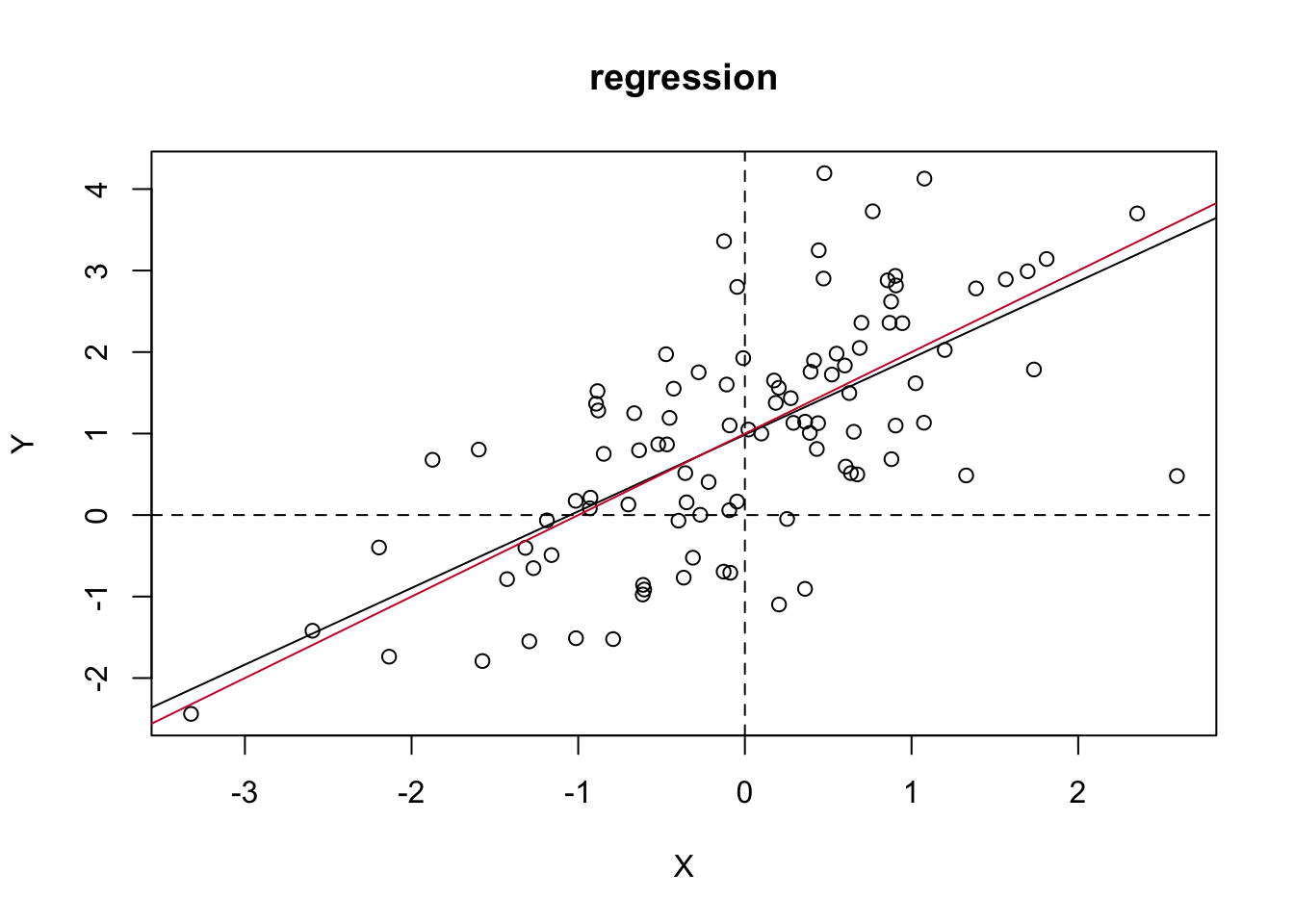
Step 3 (additional): plot the regression graph with the scatter points and the regression line. Further compare the regression line (black) with the true coefficient line (red).
# plotplot(y = Y, x = X[,2], xlab ="X", ylab ="Y", main ="regression")abline(a = bhat[1], b = bhat[2])abline(a = b0[1], b = b0[2], col ="#CC0035")abline(h =0, lty =2)abline(v =0, lty =2)
Step 4: In econometrics we are often interested in hypothesis testing. The t-statistic is widely used. To test the null \(H_0: \beta_1 = 1\), we compute the associated t-statistic. Again, this is a translation. \[
t = \frac{\hat{\beta}_1 - \beta_{01}}{ \hat{\sigma}_{\hat{\beta}_1} }
= \frac{\hat{\beta}_1 - \beta_{01}}{ \sqrt{ \left[ (X'X)^{-1} \hat{\sigma}^2 \right]_{22} } }.
\] where \([\cdot]_{22}\) is the (2,2)-element of a matrix.
# calculate the t-valuebhat2 = bhat[2] # the parameter we want to teste_hat = Y - X %*% bhatsigma_hat_square =sum(e_hat^2)/ (n-2)Sigma_B =solve( t(X) %*% X ) * sigma_hat_squaret_value_2 = ( bhat2 - b0[2]) /sqrt( Sigma_B[2,2] )print(t_value_2)
[1] -0.5615293
Exercise (in Homework 1): Can you write a function with both \(\hat{\beta}\) and \(t\)-value as outputs?
Accessing function source code
Looking inside a function is not only important for debugging, but it’s also a great way to pick up programming tips and tricks. We refer to this as accessing a function’s source code. For simple functions, accessing the source is a mere matter of typing the function name into your R console (without parentheses) and letting R print the object to screen. Try this yourself with the num_to_alpha function that we created earlier, or, say, dplyr::bind_rows.
Unfortunately, the simple print-function-to-screen approach doesn’t work once you start getting into functions that have different dispatch methods (e.g. associated with S3 or S4 classes), or rely on compiled code underneath the hood (e.g. written in C or Fortran). The good news is that you can still view the source code, even if that sometimes requires a bit more legwork. See Joshua Ulrich’s StackOverflow Q/A here, or Jenny Bryan’s summary here. Lastly, Jim Hester’s lookup package can do all of the legwork for you if don’t feel like dealing with any complications.
Packages
While a base R installation is relatively compact, R’s true power lies in its extensive ecosystem of add-on packages. This rich package ecosystem is one of R’s greatest strengths. Most packages are hosted on CRAN (the Comprehensive R Archive Network).
A common practice in the statistical community is for researchers to develop and publish R packages alongside their academic papers, making new statistical methods immediately accessible to practitioners. This creates a virtuous cycle: researchers gain visibility for their work, while users benefit from cutting-edge statistical tools often available within months (or even weeks) of publication.
Install and load packages
A package can be installed by install.packages("package_name") and invoked by library(package_name).
For example, to install the ggplot2 package, you can either:
Console: Enter install.packages("ggplot2").
RStudio: Click the “Packages” tab in the bottom-right window pane. Then click “Install” and search for this package.
Once the packages are installed, load them into your R session with the library() function.
library(ggplot2)
Note
Notice too that you don’t need quotes around the package names any more.
Reason: R now recognizes these packages as defined objects with given names. (“Everything in R is an object and everything has a name.”)
Tip
PS — A convenient way to combine the package installation and loading steps is with the pacman package’sp_load() function. If you run pacman::p_load(ggplot2) it will first look to see whether it needs to install either package before loading them. Clever. - We’ll get to this next week, but if you want to run a function from an (installed) package without loading it, you can use the PACKAGE::package_function() syntax.
Tip
Recall that we can run a function from an (installed) package without loading it by using the PACKAGE::package_function() syntax.
stats::sd(1:10)
[1] 3.02765
Many authors also distribute packages through GitHub or their personal websites, especially for cutting-edge research or development versions. You can install these packages using either the devtools or remotes package, following the specific installation instructions provided on the project’s repository. For instance, the RDHonest package provides clear installation instructions on its GitHub page.
if (!requireNamespace("remotes")) {install.packages("remotes")}remotes::install_github("kolesarm/RDHonest")
Keep your R session’s working directory at the package root.
Iterate with devtools::load_all() for fast feedback.
Run devtools::check() often to catch issues early.
Step 1 — Create a package skeleton
usethis::create_package("~/dev/eco4370") # choose your path# RStudio will open the new project; from there:usethis::use_git() # initialize Git repousethis::use_mit_license("Your Name") # add a license
Edit DESCRIPTION early (Title, Description, Authors, Imports). Prefer Imports: over Depends: and keep versions pinned only when needed.
Step 2 — Add functions (with roxygen docs)
Create an R script and a function:
usethis::use_r("math") # creates R/math.R
# file: R/math.R#' Add two numbers#'#' @param x numeric#' @param y numeric#' @return numeric#' @export#' @examples#' add(1, 2)add <-function(x, y) { x + y}
Generate docs + namespace and try it without installing:
devtools::document() # creates man/*.Rd and updates NAMESPACEdevtools::load_all() # simulate attach for developmentadd(1, 2)
Edit → document → load_all → test → check is the core loop for fast feedback.
usethis::use_package("forcats") # adds to Imports# call explicitly as forcats::fct_unify(...),# unless you import specific functions with @importFrom in roxygen
Best practices:
Prefer pkg::fun() in code.
Avoid library() inside package code.
Keep Imports: tidy and alphabetical in DESCRIPTION.
Step 5 — Project hygiene & style
Group related functions together (avoid one giant file or one-file-per-tiny-function).
Avoid global side-effects: no setwd(), options(), par(), Sys.setenv(), set.seed() in package code.
Never use source() or library() inside R/ package code.
Style regularly:
styler::style_pkg()
Step 6 — README, GitHub, and visibility
usethis::use_readme_rmd()devtools::build_readme()usethis::use_github() # creates remote, sets origin, and optionally pushes
This makes your package discoverable and easier to collaborate on.
Step 7 — Vignettes & data
Vignette (long-form docs):
usethis::use_vignette("eco4370-intro")# Knit within the vignette to preview; pkg build will render it
Data
User-facing datasets go in data/ via use_data() (document in R/data.R); never @export datasets.
Internal data for functions: use_data(..., internal = TRUE) → R/sysdata.rda (no help file needed).
Raw sources/scripts that create data: data-raw/ (and add data-raw to .Rbuildignore).
#' Small Car Dataset#'#' A tiny excerpt of mtcars for examples.#'#' @format A data frame with 8 rows and 4 variables.#' @source Base R `mtcars`"cars_small"
Step 8 — Check, install, build
devtools::check() # CRAN-style QAdevtools::install() # local installdevtools::build() # source tarball; build(binary = TRUE) for binary on your OS
#' Small Car Dataset#'#' A tiny excerpt of mtcars for examples.#'#' @format A data frame with 8 rows and 4 variables.#' @source Base R `mtcars`"cars_small"
For internal helper data: usethis::use_data(obj, internal = TRUE) → R/sysdata.rda (no help file).
5) Vignette
usethis::use_vignette("getting-started")
Edit vignettes/getting-started.Rmd:
# markdown---title:"Getting Started with eco4370"output: rmarkdown::html_vignettevignette:> %\VignetteIndexEntry{Getting Started} %\VignetteEngine{knitr::rmarkdown} %\VignetteEncoding{UTF-8}---
Basic usage
add(10, 5)movavg(1:10, k =3)cars_small
Preview by knitting; when building the package, vignettes are rendered automatically.
6) README and GitHub
usethis::use_readme_rmd()devtools::build_readme()usethis::use_github() # requires a GitHub account + token set up
A modern approach to developing R packages is through literate programming. The litr package, developed by Jacob Bien, enables you to write complete R packages within a single R Markdown document. The R package is created when you knit the Rmd file. For larger packages, you can write a bookdown that defines the package.
If you are interested in this approach, you can watch videos to quickly see how it works.
Control flow
Now that we’ve got a good sense of the basic function syntax, it’s time to learn control flow. That is, we want to control the order (or “flow”) of statements and operations that our functions evaluate.
This is common in all programming languages. if is used for choice, and for or while is used for loops, etc.
if and ifelse
The basic syntax for an if statement is:
if (CONDITION) { OPERATION}
A simple example is:
square_root =function(x) {if (x <0) {message("x is negative")return(NA) }return(sqrt(x))}square_root(9)
[1] 3
square_root(-9)
x is negative
[1] NA
We can extend this with an else statement to handle alternative conditions:
The base R ifelse() function normally works great and I use it all the time. However, there are a couple of “gotcha” cases that you should be aware of. Consider the following (silly) function which is designed to return either today’s date, or the day before.
You are no doubt surprised to find that our function returns a number instead of a date. This is because ifelse() automatically converts date objects to numeric as a way to get around some other type conversion strictures. Confirm for yourself by converting it back the other way around with: as.Date(today(TRUE), origin = "1970-01-01").
Aside: The “dot-dot-dot” argument (...) that I’ve used above is a convenient shortcut that allows users to enter unspecified arguments into a function. This is beyond the scope of our current lecture, but can prove to be an incredibly useful and flexible programming strategy. I highly encourage you to look at the relevant section of Advanced R to get a better idea.
To guard against this type of unexpected behaviour, as well as incorporate some other optimisations, both the tidyverse (through dplyr) and data.table offer their own versions of ifelse statements. I won’t explain these next code chunks in depth (consult the relevant help pages if needed), but here are adapted versions of our today() function based on these alternatives.
As you may have guessed, it’s certainly possible to write nested ifelse() statements. For example,
ifelse(CONDITION1, DO IF TRUE, ifelse(CONDITION2, DO IF TRUE, ifelse(...)))
or
if (CONDITION1) { DO IF TRUE} elseif (CONDITION2) { DO IF TRUE} else { DO IF FALSE}
However, these nested statements quickly become difficult to read and troubleshoot. A better solution was originally developed in SQL with the CASE WHEN statement. Both dplyr with case_when() and data.table with fcase() provide implementations R. Here is a simple illustration of both implementations.
x =1:10## dplyr::case_when()case_when( x <=3~"small", x <=7~"medium",TRUE~"big"## Default value. Could also write `x > 7 ~ "big"` here. )
Alongside control flow, the most important early programming skill to master is iteration. In particular, we want to write functions that can iterate — or map — over a set of inputs.
for loops
By far the most common way to iterate across different programming languages is for loops.
When we use loops, we should minimize the tasks within the loop. One principle is that we should always pre-specify the dimension and allocate memory for variables outside the loop, noting that in cases where we want to “grow” an object via a for loop, we first have to create an empty (or NULL) object.
Example Empirical coverage of confidence intervals.
CI <-function(x) { # construct confidence interval# x is a vector of random variables n <-length(x) mu <-mean(x) sig <-sd(x) upper <- mu +1.96/sqrt(n) * sig lower <- mu -1.96/sqrt(n) * sigreturn(list(lower = lower, upper = upper))}Rep <-100000sample_size <-1000mu <-2# Append a new outcome after each loop pts0 <-Sys.time() # check time for (i in1:Rep) { x <-rpois(sample_size, mu) bounds <-CI(x) out_i <- ((bounds$lower <= mu) & (mu <= bounds$upper)) if (i ==1) { out <- out_i } else { out <-c(out, out_i) }}mean(out)
[1] 0.95023
cat("Takes", Sys.time() - pts0, "seconds\n")
Takes 8.736682 seconds
# Initialize the result vectorout <-rep(0, Rep) pts0 <-Sys.time() # check time for (i in1:Rep) { x <-rpois(sample_size, mu) bounds <-CI(x) out[i] <- ((bounds$lower <= mu) & (mu <= bounds$upper)) }mean(out)
[1] 0.94893
cat("Takes", Sys.time() - pts0, "seconds\n")
Takes 3.044395 seconds
Vectorization
Before we write any loops, we should ask ourselves: “Do I need to iterate at all?”
R is vectorized - often times you can apply a function to every element of a vector at once, rather than one at a time.
In R and other high-level languages, for loops can be slow. When you need to loop through many elements and perform expensive operations on each one, your code may take a long time to execute. Vectorization is one effective way to speed up such operations.
Many operations that are typically implemented using for-loops can be rewritten using vectorized operations or matrix computations. Whenever possible, you should leverage R’s built-in vectorization capabilities for better performance.
Example: 2-D Random Walk
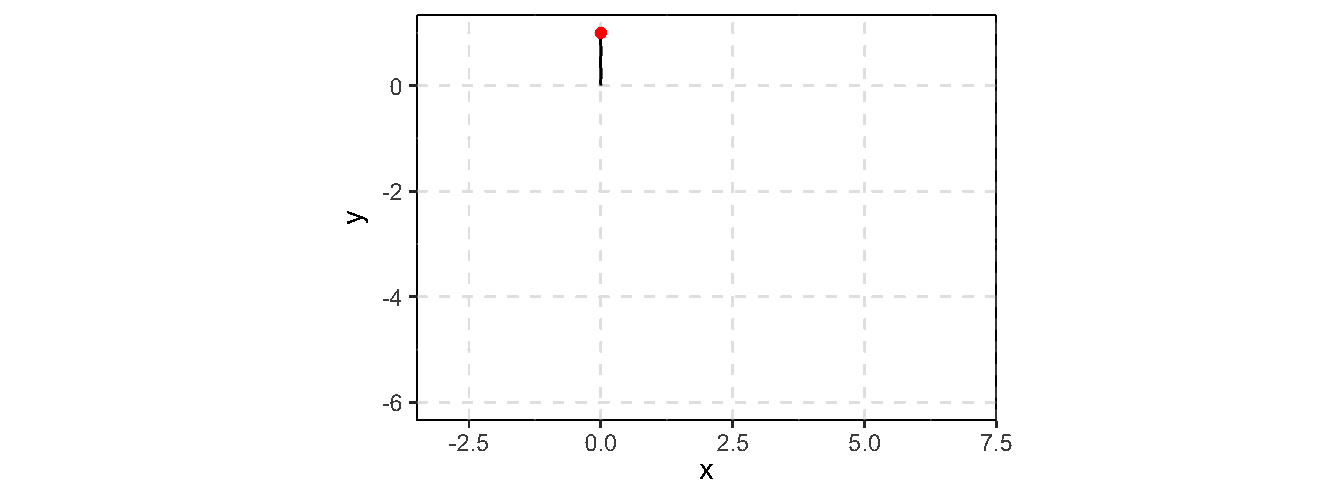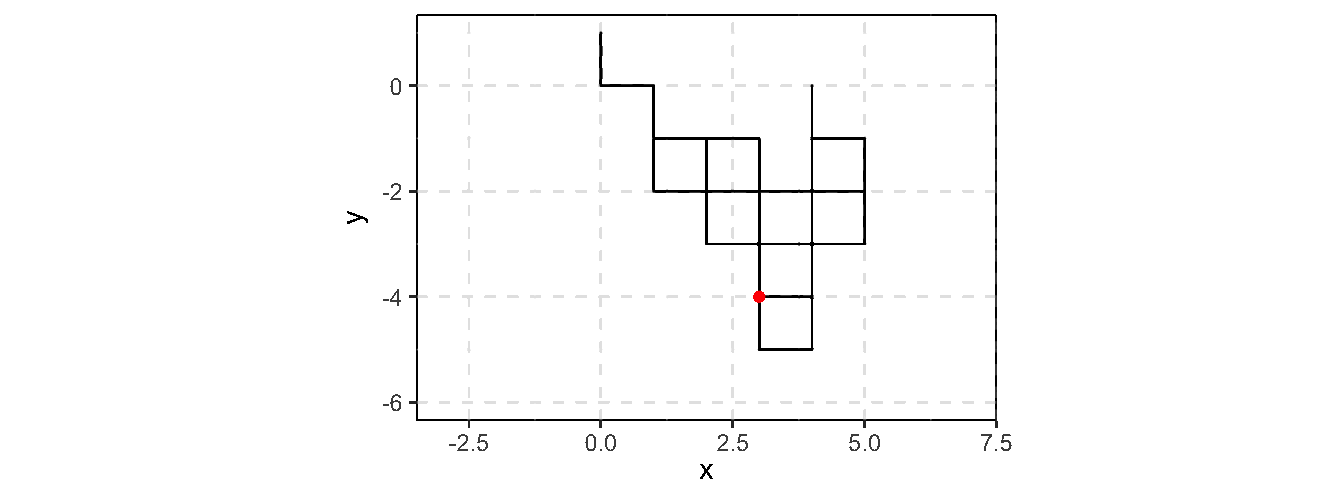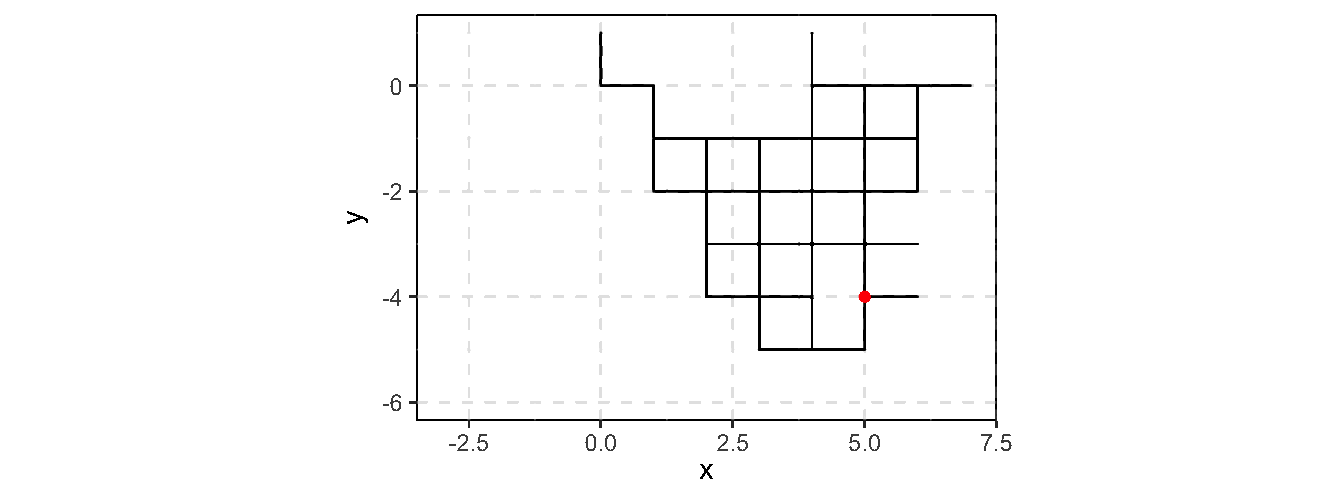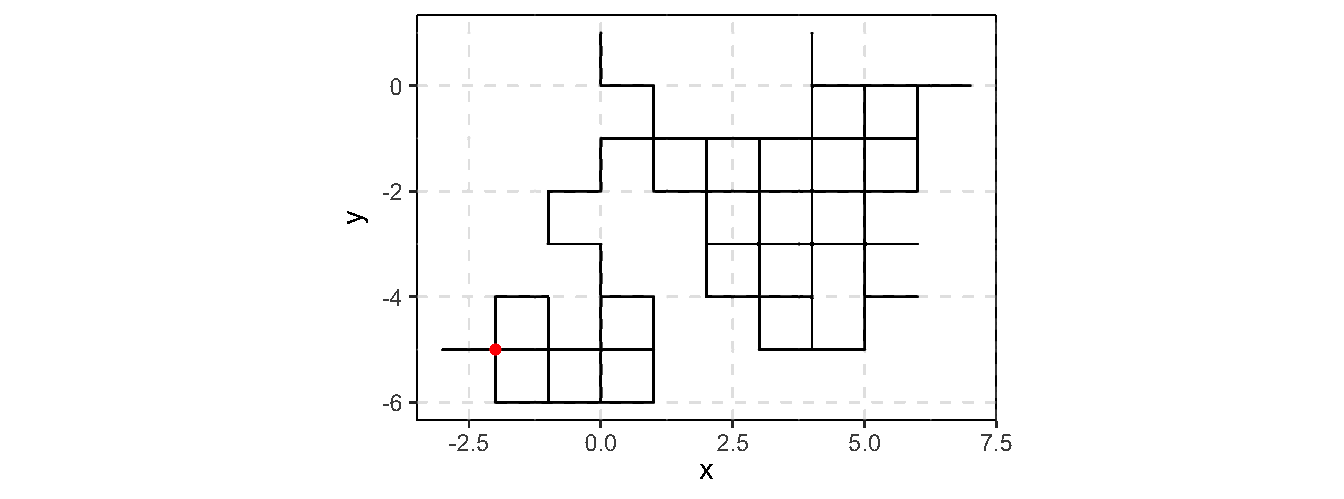
Consider an example of generating 2-D random walk (example borrowd from Ross Ihaka’s online note)
A 2-D discrete random walk:
Start at the point \((0, 0)\)
For \(t = 1, 2, \cdots\), take a unit step in a randomly chosen direction
rw2d_vec <-function(n) { xsteps <-c(-1, 1, 0, 0) ysteps <-c(0, 0, -1, 1) dir <-sample(1:4, n -1, replace =TRUE) xpos <-c(0, cumsum(xsteps[dir])) ypos <-c(0, cumsum(ysteps[dir]))return(data.frame(x = xpos, y = ypos))}
Comparison
n <-100000t0 <-Sys.time()df <-rw2d_loop(n)cat("Naive implementation: ", difftime(Sys.time(), t0, units ="secs"))
Naive implementation: 0.3849299
t0 <-Sys.time()df2 <-rw2d_vec(n)cat("Vectorized implementation: ", difftime(Sys.time(), t0, units ="secs"))
Vectorized implementation: 0.002048969
Example: Standard Error under Heteroskedasticity
In linear regression model with heteroskedasticity, the asymptotic distribution of the OLS estimator is \[
\sqrt{n}\left(\widehat{\beta}-\beta_0\right) \stackrel{d}{\rightarrow} N\left(0, E\left[x_i x_i^{\prime}\right]^{-1} \operatorname{var}\left(x_i e_i\right) E\left[x_i x_i^{\prime}\right]^{-1}\right)
\] where \(\operatorname{var}\left(x_i e_i\right)\) is estimated by
lpm <-function(n) {# set the parameters b0 <-matrix(c(-1, 1), nrow =2)# generate the data from a Probit model e <-rnorm(n) X <-cbind(1, rnorm(n)) Y <-as.numeric(X %*% b0 + e >=0)# note that in this regression bhat does not converge to b0 # because the model is mis-specified# OLS estimation bhat <-solve(t(X) %*% X, t(X) %*% Y) e_hat <- Y - X %*% bhatreturn(list(X = X, e_hat =as.vector(e_hat)))}
n = 2000 , Rep = 1000 , opt = 1 , time = 4.116201
n = 2000 , Rep = 1000 , opt = 2 , time = 15.24552
n = 2000 , Rep = 1000 , opt = 3 , time = 0.2393119
n = 2000 , Rep = 1000 , opt = 4 , time = 0.04152393
Parallel loops
We can exploit the power of multicore machines to speed up loops by parallel computing. The packages foreach and doParallel are useful for parallel computing.
capture <-function() { x <-rpois(sample_size, mu) bounds <-CI(x)return(((bounds$lower <= mu) & (mu <= bounds$upper)))}# Workhorse packageslibrary(foreach)library(doParallel)Rep <-100000sample_size <-1000registerDoParallel(8) # open 8 CPUs to accept incoming jobs.pts0 <-Sys.time() # check time out <-foreach(icount(Rep), .combine = c) %dopar% { x <-rpois(sample_size, mu) bounds <-CI(x) ((bounds$lower <= mu) & (mu <= bounds$upper))}cat("parallel loop takes", Sys.time() - pts0, "seconds\n")
parallel loop takes 4.12626 seconds
pts0 <-Sys.time() # check time out <-foreach(icount(Rep), .combine = c) %do% { x <-rpois(sample_size, mu) bounds <-CI(x) ((bounds$lower <= mu) & (mu <= bounds$upper))}cat("sequential loop takes", Sys.time() - pts0, "seconds\n")
sequential loop takes 8.217079 seconds
We change the nature of the task a bit.
Rep <-200sample_size <-200000pts0 <-Sys.time() # check time out <-foreach(icount(Rep), .combine = c) %dopar% { x <-rpois(sample_size, mu) bounds <-CI(x) ((bounds$lower <= mu) & (mu <= bounds$upper))}cat("parallel loop takes", Sys.time() - pts0, "seconds\n")
parallel loop takes 0.211062 seconds
pts0 <-Sys.time() # check time out <-foreach(icount(Rep), .combine = c) %do% { x <-rpois(sample_size, mu) bounds <-CI(x) ((bounds$lower <= mu) & (mu <= bounds$upper))}cat("sequential loop takes", Sys.time() - pts0, "seconds\n")
Loops can run very slowly, and there might be cases an where inconspicuous for loop has brought an entire analysis crashing to its knees.4. The bigger problem with for loops, however, is that they deviate from the norms and best practices of functional programming.
The concept of functional programming (FP) is arguably the most important thing that you can take away from today’s lecture. In his excellent book, Advanced R, Hadley Wickham explains the core idea as follows.
R, at its heart, is a functional programming (FP) language. This means that it provides many tools for the creation and manipulation of functions. In particular, R has what’s known as first class functions. You can do anything with functions that you can do with vectors: you can assign them to variables, store them in lists, pass them as arguments to other functions, create them inside functions, and even return them as the result of a function.
That may seem a little abstract, so here is video of Hadley giving a much more intuitive explanation through a series of examples.
Summary:for loops tend to emphasise the objects that we’re working with (say, a vector of numbers) rather than the operations that we want to apply to them (say, get the mean or median or whatever). This is inefficient because it requires us to continually write out the for loops by hand rather than getting an R function to create the for-loop for us.
As a corollary, for loops also pollute our global environment with the variables that are used as counting variables. Take a look at your “Environment” pane in RStudio. What do you see? In addition to the objects we created, we also see two variables i (equal to the last value of their respective loops). Creating these auxiliary variables is almost certainly not an intended outcome when your write a for-loop.5 More worringly, they can cause programming errors when we inadvertently refer to a similarly-named variable elsewhere in our script. So we best remove them manually as soon as we’re finished with a loop.
rm(i)
Another annoyance arrived in cases where we want to “grow” an object as we iterate over it (see our examples). In order to do this with a for loop, we had to go through the rigmarole of creating an empty object first.
FP allows to avoid the explicit use of loop constructs and its associated downsides. In practice, there are two ways to implement FP in R:
Base R contains a very useful family of *apply functions. I won’t go through all of these here — see ?apply or this blog post among numerous excellent resources — but they all follow a similar philosophy and syntax. The good news is that this syntax very closely mimics the syntax of basic for-loops. For example, consider the code below, which is analgous to our first for loop above, but now invokes a base::lapply() call instead.
# for(i in 1:10) print(LETTERS[i]) ## Our original for loop (for comparison)lapply(1:10, function(i) LETTERS[i])
First, check your “Environment” pane in RStudio. Do you see an object called “i” in the Global Environment? (The answer should be”no”.) Again, this is because of R’s lexical scoping rules, which mean that any object created and invoked by a function is evaluated in a sandboxed environment outside of your global environment.
Second, notice how little the basic syntax changed when switching over from for() to lapply(). Yes, there are some differences, but the essential structure remains the same: We first provide the iteration list (1:10) and then specify the desired function or operation (LETTERS[i]).
Third, notice that the returned object is a list. The lapply() function can take various input types as arguments — vectors, data frames, lists — but always returns a list, where each element of the returned list is the result from one iteration of the loop. (So now you know where the “l” in “lapply” comes from.)
Okay, but what if you don’t want the output in list form? There several options here.6 However, the method that I use most commonly is to bind the different list elements into a single data frame with either dplyr::bind_rows() or data.table::rbindlist(). For example, here’s a a slightly modified version of our function that now yields a data frame:
lapply(1:10, function(i) { df =tibble(num = i, let = LETTERS[i])return(df) }) %>%bind_rows()
# A tibble: 10 × 2
num let
<int> <chr>
1 1 A
2 2 B
3 3 C
4 4 D
5 5 E
6 6 F
7 7 G
8 8 H
9 9 I
10 10 J
Taking a step back, while the default list-return behaviour may not sound ideal at first, I’ve found that I use lapply() more frequently than any of the other apply family members. A key reason is that my functions normally return multiple objects of different type (which makes lists the only sensible format)… or a single data frame (which is where dplyr::bind_rows() or data.table::rbindlist() come in).
Note
The *apply has a large family of variants.
An option that would work well in the this particular case is sapply(), which stands for “simplify apply”. This is essentially a wrapper around lapply that tries to return simplified output that matches the input type. If you feed the function a vector, it will try to return a vector, etc.
sapply(1:10, function(i) LETTERS[i])
[1] "A" "B" "C" "D" "E" "F" "G" "H" "I" "J"
Another useful member of the *apply family is apply(), which applies functions over array margins (rows or columns of matrices/data frames). Here’s a quick example:
# Create a simple matrixmat <-matrix(1:12, nrow =3, ncol =4)print(mat)
If you’re in the market for a more concise overview of the different *apply() functions, then I recommend this blog post by Neil Saunders.
2) purrr package
The tidyverse offers its own enhanced implementation of the base *apply() functions through the purrr package.7 The key function to remember here is purrr::map(). And, indeed, the syntax and output of this command are effectively identical to base::lapply():
map(1:10, function(i) { ## only need to swap `lapply` for `map` df =tibble(num = i, let = LETTERS[i])return(df) })
[[1]]
# A tibble: 1 × 2
num let
<int> <chr>
1 1 A
[[2]]
# A tibble: 1 × 2
num let
<int> <chr>
1 2 B
[[3]]
# A tibble: 1 × 2
num let
<int> <chr>
1 3 C
[[4]]
# A tibble: 1 × 2
num let
<int> <chr>
1 4 D
[[5]]
# A tibble: 1 × 2
num let
<int> <chr>
1 5 E
[[6]]
# A tibble: 1 × 2
num let
<int> <chr>
1 6 F
[[7]]
# A tibble: 1 × 2
num let
<int> <chr>
1 7 G
[[8]]
# A tibble: 1 × 2
num let
<int> <chr>
1 8 H
[[9]]
# A tibble: 1 × 2
num let
<int> <chr>
1 9 I
[[10]]
# A tibble: 1 × 2
num let
<int> <chr>
1 10 J
Given these similarities, I won’t spend much time on purrr. Although, I do think it will be the optimal entry point for many you when it comes to programming and iteration. You have already learned the syntax, so it should be very easy to switch over. However, one additional thing I wanted to flag for today is that map() also comes with its own variants, which are useful for returning objects of a desired type. For example, we can use purrr::map_df() to return a data frame.
map_df(1:10, function(i) { ## don't need bind_rows with `map_df` df =tibble(num = i, let = LETTERS[i])return(df) })
# A tibble: 10 × 2
num let
<int> <chr>
1 1 A
2 2 B
3 3 C
4 4 D
5 5 E
6 6 F
7 7 G
8 8 H
9 9 I
10 10 J
Note that this is more efficient (i.e. involves less typing) than the lapply() version, since we don’t have to go through the extra step of binding rows at the end.
Note
On the other end of the scale, Jenny Bryan (all hail) has created a fairly epic purrr tutorial mini-website. (Bonus: She goes into more depth about working with lists and list columns.)
Create and iterate over named functions
As you may have guessed already, we can split the function and the iteration (and binding) into separate steps. This is generally a good idea, since you typically create (named) functions with the goal of reusing them.
## Create a named functionnum_to_alpha =function(i) { df =tibble(num = i, let = LETTERS[i])return(df) }
Now, we can easily iterate over our function using different input values. For example,
lapply(1:10, num_to_alpha) %>%bind_rows()
# A tibble: 10 × 2
num let
<int> <chr>
1 1 A
2 2 B
3 3 C
4 4 D
5 5 E
6 6 F
7 7 G
8 8 H
9 9 I
10 10 J
Or, say
map_df(c(1, 5, 26, 3), num_to_alpha)
# A tibble: 4 × 2
num let
<dbl> <chr>
1 1 A
2 5 E
3 26 Z
4 3 C
Iterate over multiple inputs
Thus far, we have only been working with functions that take a single input when iterating. For example, we feed them a single vector (even though that vector contains many elements that drive the iteration process). But what if we want to iterate over multiple inputs? Consider the following function, which takes two separate variables x and y as inputs, combines them in a data frame, and then uses them to create a third variable z.
Note: Again, this is a rather silly function that we could easily improve upon using standard (vectorised) tools. But my goal here is to demonstrate programming principles with simple examples that carry over to more complicated cases where vectorisation is not possible.
## Create a named functionmulti_func =function(x, y) { df =tibble(x = x, y = y) %>%mutate(z = (x + y)/sqrt(x))return(df) }
Before continuing, quickly test that it works using non-iterated inputs.
multi_func(1, 6)
# A tibble: 1 × 3
x y z
<dbl> <dbl> <dbl>
1 1 6 7
Great, it works. Now let’s imagine that we want to iterate over various levels of both x and y. There are two basics approaches that we can follow to achieve this:
Use base::mapply() or purrr::pmap().
Use a data frame of input combinations.
I’ll quickly review both approaches, continuing with the multi_func() function that we just created above.
1) Use mapply() or pmap()
Both base R — through mapply() — and purrr — through pmap — can handle multiple input cases for iteration. The latter is easier to work with in my opinion, since the syntax is closer (nearly identical) to the single input case. Still, I’ll demonstrate using both versions below.
First, base::mapply():
## Note that the inputs are now moved to the *end* of the call. ## Also, mapply() is based on sapply(), so we also have to tell it not to ## simplify if we want to keep the list structure.mapply( multi_func,x =1:5, ## Our "x" vector inputy =6:10, ## Our "y" vector inputSIMPLIFY =FALSE## Tell it not to simplify to keep the list structure ) %>%bind_rows()
# A tibble: 5 × 3
x y z
<int> <int> <dbl>
1 1 6 7
2 2 7 6.36
3 3 8 6.35
4 4 9 6.5
5 5 10 6.71
Second, purrr::pmap():
## Note that the inputs are combined in a list.pmap_df(list(x=1:5, y=6:10), multi_func)
# A tibble: 5 × 3
x y z
<int> <int> <dbl>
1 1 6 7
2 2 7 6.36
3 3 8 6.35
4 4 9 6.5
5 5 10 6.71
2) Using a data frame of input combinations
While the above approaches work perfectly well, I find that I don’t actually use either all that much in practice. Rather, I prefer to “cheat” by feeding multi-input functions a single data frame that specifies the necessary combination of variables by row. I’ll demonstrate how this works in a second, but first let me explain why.
It basically boils down to the fact that I feel this gives me more control over my functions and inputs.
I don’t have to worry about accidentally feeding separate inputs of different lengths. Try running the above functions with an x vector input of 1:10, for example. (Leave everything else unchanged.) pmap() will at least fail to iterate and give you a helpful message, but mapply will actually complete with totally misaligned columns. Putting everything in a (rectangular) data frame forces you to ensure the equal length of inputs a priori.
Similarly, I often need to run a function over all possible combinations of different inputs.8 So it’s convenient for me to use this data frame as an input directly in my function.
In my view, it’s just simpler and cleaner to keep things down to a single input. This will be harder to see in the simple example that I’m going to present next. But I’ve found that it can make a big difference with complicated functions that have a lot of nesting (i.e. functions of functions) and/or parallelization.
Those justifications aside, let’s see how this might work with an example. Consider the following function:
parent_func =## Main function: Takes a single data frame as an inputfunction(input_df) { df =## Nested iteration functionmap_df(1:nrow(input_df), ## i.e. Iterate (map) over each row of the input data framefunction(n) {## Extract the `x` and `y` values from row "n" of the data frame x = input_df$x[n] y = input_df$y[n]## Use the extracted values df =multi_func(x, y)return(df) })return(df) }
There are three conceptual steps to the above code chunk:
First, I create a new function called parent_func(), which takes a single input: a data frame containing x and y columns (and potentially other columns too).
This input data frame is then passed to a second (nested) function, which will iterate over the rows of the data frame.
During each iteration, the x and y values for that row are passed to our original multi_func() function. This will return a data frame containing the desired output.
Let’s test that it worked using two different input data frames.
## Case 1: Iterate over x=1:5 and y=6:10input_df1 =tibble(x=1:5, y=6:10)parent_func(input_df1)
# A tibble: 5 × 3
x y z
<int> <int> <dbl>
1 1 6 7
2 2 7 6.36
3 3 8 6.35
4 4 9 6.5
5 5 10 6.71
## Case 2: Iterate over *all possible combinations* of x=1:5 and y=6:10input_df2 =expand.grid(x=1:5, y=6:10)# input_df2 = expand(input_df1, x, y) ## Also worksparent_func(input_df2)
I basically just had to tell R that I wanted to implement the iteration in parallel (i.e. plan(multisession)) and slightly amend my lapply() call (i.e. future_lapply()).
For those of you who prefer the purrr::map() family of functions for iteration and are feeling left out; don’t worry. The furrr package (link) has you covered. Once again, the syntax for these parallel functions will be very little changed from their serial versions. We simply have to tell R that we want to run things in parallel with plan(multisession) and then slightly amend our map call to future_map_dfr().9
R is a language created by statisticians. It has elegant built-in statistical functions. p (probability), d (density for a continuous random variable, or mass for a discrete random variable), q (quantile), r (random variable generator) are used ahead of the name of a probability distribution, such as norm (normal), chisq (\(\chi^2\)), t (t), weibull (Weibull), cauchy (Cauchy), binomial (binomial), pois (Poisson), to name a few.
Example
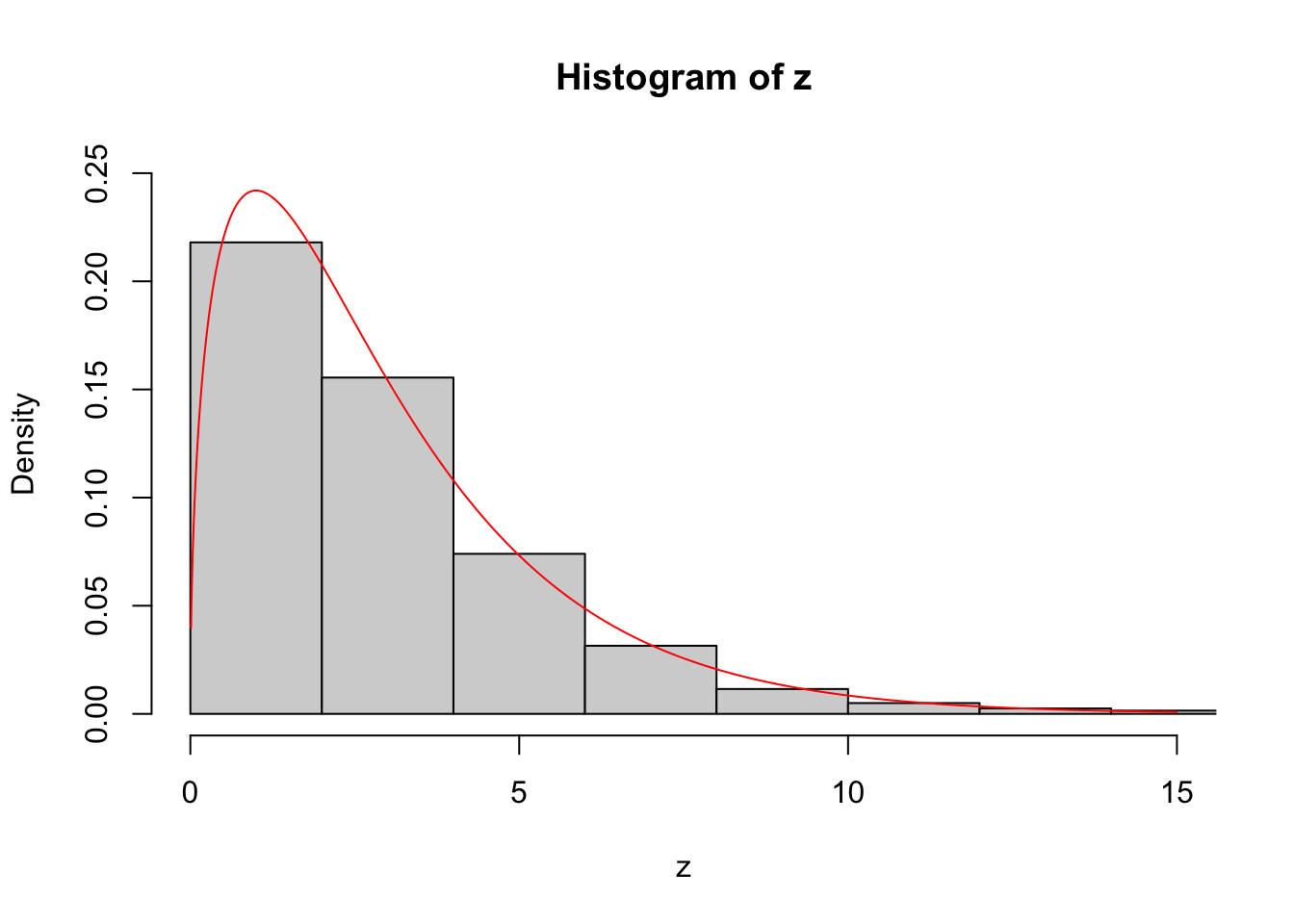
This example illustrates the sampling error.
Plot the density of \(\chi^2(3)\) over an equally spaced grid system x_axis = seq(0.01, 15, by = 0.01) (black line).
Generate 1000 observations from \(\chi^2(3)\) distribution. Plot the kernel density, a nonparametric estimation of the density (red line).
set.seed(100)x_axis <-seq(0.01, 15, by =0.01)y <-dchisq(x_axis, df =3)z <-rchisq(1000, df =3)hist(z, freq =FALSE, xlim =range(0.01, 15), ylim =range(0, 0.25))lines(y = y, x = x_axis, type ="l", xlab ="x", ylab ="density", col ="red")
Statistical models are formulated as y~x, where y on the left-hand side is the dependent variable, and x on the right-hand side is the explanatory variable. The built-in OLS function is lm. It is called by lm(y~x, data = data_frame).
All built-in regression functions in R share the same structure. Once one type of regression is understood, it is easy to extend to other regressions.
# Linear modelsn <-100x <-rnorm(n) y <-0.5+1* x +rnorm(n)result <-lm(y ~ x)summary(result)
Call:
lm(formula = y ~ x)
Residuals:
Min 1Q Median 3Q Max
-2.49919 -0.53555 -0.08413 0.46672 2.74626
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.43953 0.09161 4.798 5.74e-06 ***
x 1.03031 0.10158 10.143 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.9091 on 98 degrees of freedom
Multiple R-squared: 0.5122, Adjusted R-squared: 0.5072
F-statistic: 102.9 on 1 and 98 DF, p-value: < 2.2e-16
class(result)
[1] "lm"
typeof(result)
[1] "list"
result$coefficients
(Intercept) x
0.4395307 1.0303095
An simple example of logit regression using the Swiss Labor Market Participation Data (Cross-section data originating from the health survey SOMIPOPS for Switzerland in 1981).
participation income age education youngkids oldkids foreign
1 no 10.78750 3.0 8 1 1 no
2 yes 10.52425 4.5 8 0 1 no
3 no 10.96858 4.6 9 0 0 no
4 no 11.10500 3.1 11 2 0 no
5 no 11.10847 4.4 12 0 2 no
6 yes 11.02825 4.2 12 0 1 no
SwissLabor <- SwissLabor %>%mutate(participation =ifelse(participation =="yes", 1, 0))glm_fit <-glm( participation ~ age + education + youngkids + oldkids + foreign, data = SwissLabor, family ="binomial")summary(glm_fit)
Call:
glm(formula = participation ~ age + education + youngkids + oldkids +
foreign, family = "binomial", data = SwissLabor)
Coefficients:
Estimate Std. Error z value Pr(>|z|)
(Intercept) 2.085961 0.540535 3.859 0.000114 ***
age -0.527066 0.089670 -5.878 4.16e-09 ***
education -0.001298 0.027502 -0.047 0.962371
youngkids -1.326957 0.177893 -7.459 8.70e-14 ***
oldkids -0.072517 0.071878 -1.009 0.313024
foreignyes 1.353614 0.198598 6.816 9.37e-12 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
(Dispersion parameter for binomial family taken to be 1)
Null deviance: 1203.2 on 871 degrees of freedom
Residual deviance: 1069.9 on 866 degrees of freedom
AIC: 1081.9
Number of Fisher Scoring iterations: 4
We will revisit the regression models in more detail in the later lectures.
Rmarkdown and Quarto
R Markdown is a document format that combines the power of R programming with the simplicity of Markdown syntax. It allows you to create dynamic documents where code, results, and narrative text coexist seamlessly.
R Markdown provides an authoring framework for data science. You can use a single R Markdown file to both
save and execute code
generate high quality reports that can be shared with an audience
Key Features of R Markdown
Reproducible Research: Your analysis and results are automatically updated when you change your code or data
Multiple Output Formats: Generate HTML, PDF, Word documents, presentations, and more from the same source
Code Integration: Embed R code chunks that execute and display results inline with your text
Version Control Friendly: Plain text format works well with Git and other version control systems
Basic Structure
An R Markdown document consists of three main components:
YAML Header: Contains metadata and output options (enclosed by ---)
Markdown Text: Regular text formatted with Markdown syntax
Code Chunks: R code blocks enclosed by triple backticks with {r}
Code Chunks
Code chunks are the heart of R Markdown. They allow you to: - Execute R code and display results - Control output with chunk options (e.g., echo=FALSE, eval=FALSE) - Create plots, tables, and other visualizations - Cache results for faster compilation
Getting Started
A friendly introduction to R Markdown by RStudio: https://rmarkdown.rstudio.com/lesson-1.html
For more advanced features and examples, see the R Markdown Cookbook: https://bookdown.org/yihui/rmarkdown-cookbook/
Quarto
Quarto (.qmd) represents the next generation of R Markdown, building upon its foundation while introducing significant improvements. While most R Markdown syntax remains compatible, Quarto offers enhanced features and better multi-language support beyond just R.
For comprehensive documentation and tutorials, visit the Quarto website.
Footnotes
Yes, it’s a function that let’s you write functions. Very meta.↩︎
Remember: “In R, everything is an object and everything has a name.”↩︎
E.g. Type ?rnorm and see that it provides a default mean and standard deviation of 0 and 1, respectively.↩︎
The best case I can think of is when you are trying to keep track of the number of loops, but even then there are much better ways of doing this.↩︎
For example, we could pipe the output to unlist() if you wanted a vector. Or you could use use sapply() instead, which I’ll cover shortly.↩︎
In their words: “The apply family of functions in base R solve a similar problem [i.e. to purrr], but purrr is more consistent and thus is easier to learn.”↩︎
A convenient way to do this is with base::expand.grid() — or the equivalent tidyr::expand_grid() and data.table:CJ() functions — which automatically generate a data frame of all combinations.↩︎
In this particular case, the extra “r” at the end tells future to concatenate the data frames from each iteration by rows.↩︎